Guava包为什么要提供hash
java内置的hashcode算法被限制为32位的,而且算法与数据之间耦合严重,无法进行算法的替换。虽然JDK内置的hashcode算法快,但是碰撞严重
在简单的散列表中可以通过再hash解决这个问题,但是guava官方认为在其它情况无法满足需求。
HashFunction
HashFunction是一个纯无状态函数,它将任意数据块映射到固定数量的位,其属性是相等的输入始终产生相等的输出,而不相等的输入则尽可能频繁地产生不相等的输出。
示例:常用的hash算法
// 计算MD5
System.out.println(Hashing.md5().hashBytes(input.getBytes()).toString());
System.out.println(Hashing.md5().hashString("hello, world",Charsets.UTF_8));
// 计算sha256
System.out.println(Hashing.sha256().hashBytes(input.getBytes()).toString());
// 计算sha512
System.out.println(Hashing.sha512().hashBytes(input.getBytes()).toString());
// 计算crc32
System.out.println(Hashing.crc32().hashBytes(input.getBytes()).toString());Hasher
可以向HashFunction请求有状态的哈希器,该哈希器提供流利的语法以将数据添加到哈希中,然后检索哈希值。哈希器可以接受任何原始输入,字节数组,字节数组的片段,字符序列,某些字符集中的字符序列等,或任何其他带有适当漏斗的对象
示例:
Funnel<Person> personFunnel = new Funnel<Person>() {
@Override
public void funnel(Person person, PrimitiveSink into) {
into
.putInt(person.id)
.putString(person.firstName, Charsets.UTF_8)
.putString(person.lastName, Charsets.UTF_8)
.putInt(person.birthYear);
}
};
HashFunction hf = Hashing.md5();
HashCode hc = hf.newHasher()
.putLong(11L)
.putString("www", Charsets.UTF_8)
.putObject(person, personFunnel)
.hash();Funnel
漏斗描述了对象如何Hash
Funnel<Person> personFunnel = new Funnel<Person>() {
@Override
public void funnel(Person person, PrimitiveSink into) {
into
.putInt(person.id)
.putString(person.firstName, Charsets.UTF_8)
.putString(person.lastName, Charsets.UTF_8)
.putInt(birthYear);
}
}BloomFilter 布隆过滤器
作用:布隆过滤器是一种概率数据结构,你可以测试对象是否绝对不在过滤器中,或者可能已添加到布隆过滤器中。
使用布隆过滤器,你需要实现Funnel漏斗,以便将你的对象拆解位原始类型
布隆过滤器大小该如何设定?
较大的滤波器将具有较少的误报,而较小的将为零。
估算误报率的公式是: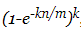 因此,你得首先确定你期望插入的数据大小n,然后尝试不同的k,m值
因此,你得首先确定你期望插入的数据大小n,然后尝试不同的k,m值
布隆过滤器hash函数的个数如何设置?
hash函数设置的越多,过滤器就越慢,同时会越快被填满。如果设置的太少,又会遇到很多误报。
因此,首先确定n的值,通过公式确定k的值 k = (m/n)ln(2)^2
布隆过滤的hash函数改如何选择?
- Chromium uses HashMix. (also, here’s a short description of how they use bloom filters)
- python-bloomfilter uses cryptographic hashes
- Plan9 uses a simple hash as proposed in Mitzenmacher 2005
- Sdroege Bloom filter uses fnv1a (included just because I wanted to show one that uses fnv.)
- Squid uses MD5
布隆过滤器的速度和空间效率
set操作和测试元素是否在过滤器中的时间复杂度都是O(k),取决与hash函数的个数
空间复杂度,取决与你能忍受的错误率以及你插入的数据潜在个数。如果数量有限,Vector表现更好,如果你不能估算潜在的插入个数,那么最好使用哈希表或可伸缩的Bloom过滤器
guava包怎么使用布隆过滤器
示例代码
@Test
public void testBloomFilter () {
// 定义漏斗,拆解对象
Funnel<Person> personFunnel = new Funnel<Person>() {
@Override
public void funnel(Person person, PrimitiveSink into) {
into
.putInt(person.id)
.putString(person.firstName, Charsets.UTF_8)
.putString(person.lastName, Charsets.UTF_8)
.putInt(person.birthYear);
}
};
Person person = Person.builder()
.id(1)
.birthYear(1995)
.firstName("Zhou")
.lastName("Evan")
.build();
// 期望插入的expectedInsertions 大小
BloomFilter<Person> bloomFilter = BloomFilter.create(personFunnel, 5000);
// 判断person是否包含在布隆过滤器中
//,如果返回false 那么就是一定不存在,如果返回True,可能存在
boolean b = bloomFilter.mightContain(person);
System.out.println(b); //false
bloomFilter.put(person);
boolean b1 = bloomFilter.mightContain(person);
System.out.println(b1);//true
}ps:
我们并没有指布隆过滤器大小,以及hash函数的个数,那么guava内部是怎么做的呢?
内部有这两个函数,来参数化过滤器大小,和hash函数的个数,函数的实现就是我们上面提到的公式的体现。
// 计算布隆过滤器大小
long numBits = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash函数的个数
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits); static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}


